从源代码到可执行程序的整个过程,可以分为四步,分别是:预编译,编译,汇编,链接。
预编译
预编译主要是处理代码中的预编译指令,预编译指令都是以#开头的,形如#define、#include、#ifdef等,其中#define是直接文本替换;#include则是把include的文件直接复制到改行所在的位置;#ifdef是用来对部分代码是否需要编译进行控制的。长得像预编译指令的#param则会保留,因为这是给传递给编译器的指令。
PS:注释在预编译阶段会被全部删除。
编译
狭义的编译就是将源代码翻译为汇编代码的过程,至于为什么说狭义,因为我们平常说的编译,一般包括了后面的汇编和链接过程。
汇编
汇编就是把汇编语言转换为机器语言,这本质上是一个查字典的过程,因为每一条汇编语句都对应着唯一的机器码(不同ISA的CPU有着不同的字典)。
链接
在以前的单文件、小软件时代,由于符号(函数或变量)的定义和对它们的引用都是在同一个文件中,其地址很方便分配与确定,但是随着软件的大型化、模块化发展,一个软件的源代码文件有几十上百个(甚至上千上万),它们生成的目标文件也有几十上百个。在它们之间,符号定义和其引用关系很复杂,一个文件中定义的符号很可能被其他文件所引用,且文件之间存在相互引用,于是导致不能在编译阶段确定符号的地址,只能采用临时地址来暂时替代最终的实际地址。
具体的符号的地址在最后一步——链接过程完成,链接细致一点又可以分为地址和空间的分配,符号决议,重定位,这三个步骤。其中第一个过程看名字就很好理解;第二个过程则是链接器检查所有的目标文件中每一个符号的引用,确保它们有且仅有有唯一的定义;第三个过程则是对目标文件中不能确定的临时地址的修正,将其修改为分配完地址后的地址。
编译器的流程
现代编译器通常集成了上述四个功能。我们现在以编译一个单一源代码文件的流程来进一步分析编译的背后流程,主要分为6个步骤:词法分析,语法分析,语义分析,中间语言生成,目标代码生成,目标代码优化。
词法分析
词法分析是将源代码输入到一个扫描器中,得到的结果是对代码中各种符号的识别分类,这里的符号包括:关键字,标识符,字面常量运算符等。为后续的语法分析奠定基础。
语法分析
语法分析是检查你所写的代码是否符合语言的语法规定。
它利用词法分析得到的记号来生成语法树。语法树就是你此法分析中得到的各种为节点的、按照你所写的代码的表达式来组织的一种树状数据结构。这里的语义分析并没有确定各种记号的具体类别,例如变量a的类型到底是int还是float,只知道它是一个变量,假如有一句b=array[a];,即使a实际是float类型,但是在语法分析阶段还是不会报错,因为这一句满足变量作为下标这一个语法,这里检查出来有错误是下一步——语义分析的工作。
一个语法树的例子,以下是表达式a=(b+4)*c;的语法树:
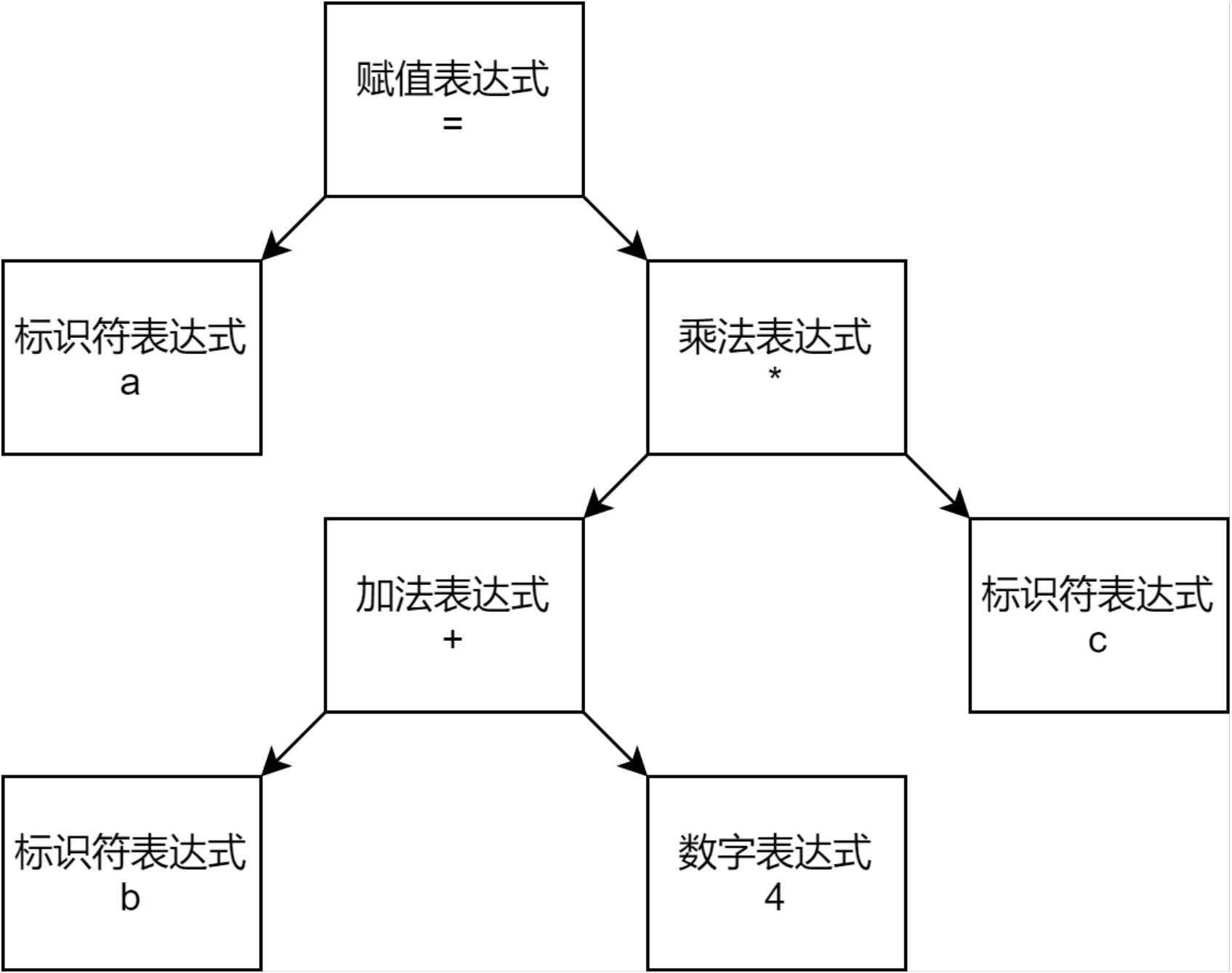
语义分析
语义分析是检查你所写的代码表达式是否是具有正确的意义,例如你把一个浮点数用作数组的下标,这在语法上是正确的,因为满足下表示一个标识符这个语法,但是这种写法并没有正确的含义,因为数组的下标是不能用浮点数表示的。
中间语言生成
中间语言生成是将源代码转换为一种,便于优化的表现形式(中间语言),一般有可以转为三地址码,P-代码等。并在这个过程中对代码进行一次优化。由于是从源码转换过来的,所以又称源码级优化。
目标代码生成与优化
中间语言生成之后就进入到了编译器后端流程。其就是将中间语言代码转换为最终目标机器平台的机器语言代码(也就是0、1组成的bit流),同时进行优化。其实这个过程就包括了之前所说的汇编过程。